OpenClaw lit the fuse on the agent conversation. How agents differ from prompts and vibe coding (state, tools, loop), and the permission-and-verification problem autonomy brings — with code.
Agents — When the Model Started Running the Loop
> Part 3 of "The Evolution of Driving LLMs." ① Prompting · ② Vibe coding · ③ Agents · ④ Harness engineering · ⑤ Open models.
Through Part 2, a human ran the loop — we built, ran, and fixed. An agent hands that loop to the model. The model uses tools itself, looks at the results, and decides the next action.
What popularized this in one stroke was OpenClaw in early 2026. An open-source autonomous agent by Austrian developer Peter Steinberger, it went from Clawdbot → Moltbot → OpenClaw (the mid renames were due to an Anthropic trademark issue) and crossed 140,000 GitHub stars. Using messengers like Telegram and Slack as its interface, it runs shell commands, the browser, files, and your calendar directly — triggered by a single text message.
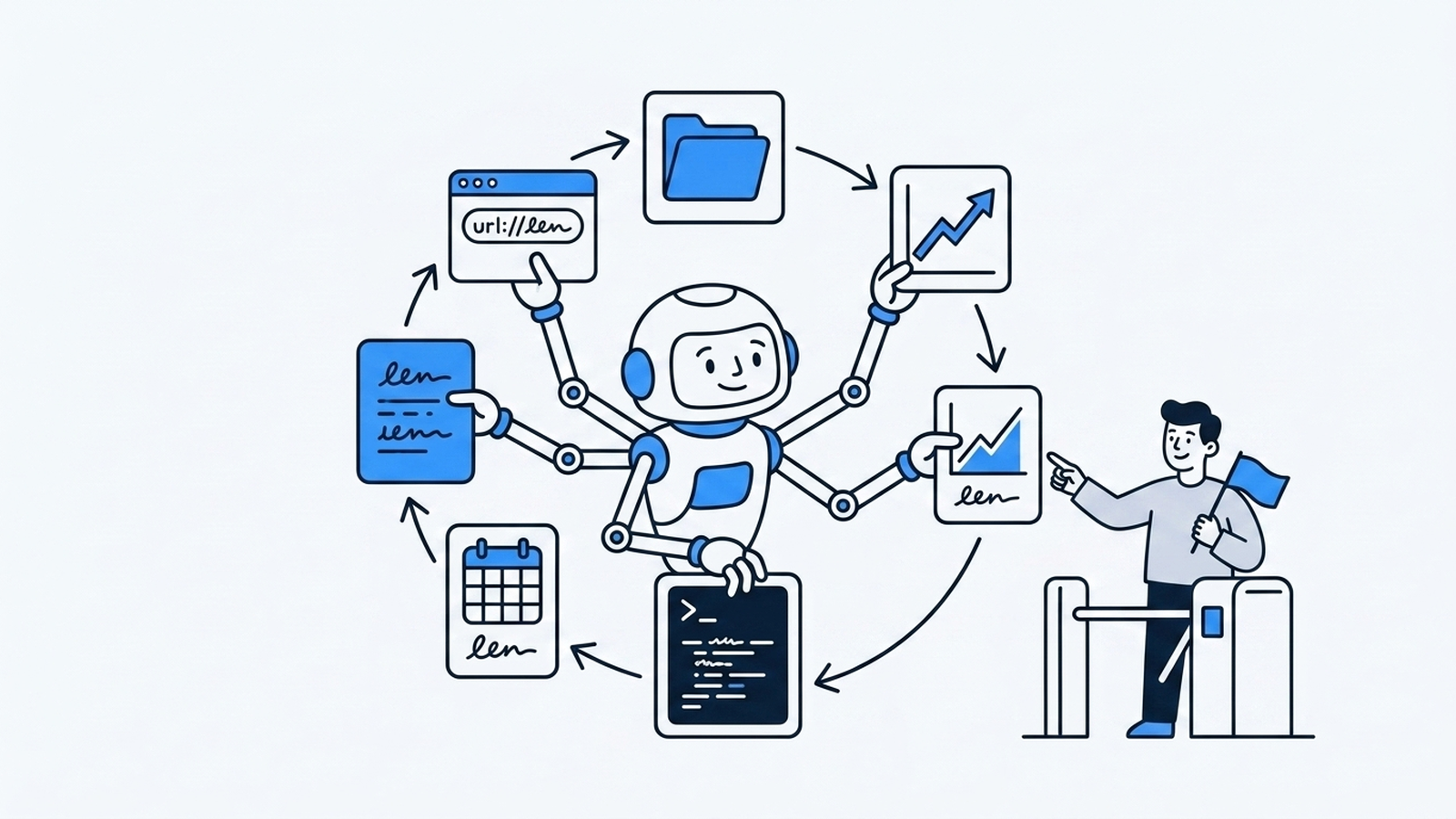
How agents differ from prompts and vibe coding
Agents fill the three limits of the earlier stages (no state, no tools, no verification) head-on.
- State — an agent carries memory of what it has done so far.
- Tools — it can take real actions: run code, read files, search.
- Loop — it doesn't answer once and stop; it repeats, deciding the next action from the result.
So an agent is essentially model + tools + loop + memory. The model is just one part of the brain; what makes an agent an agent is the loop around it. In its simplest form it looks like this.
# The essence of an agent = a perceive → plan → act → observe loop
state = memory.load()
while not done:
action = model.decide(state, tools) # plan: decide the next action
if action.is_risky: # if risky, ask a human
if not human_approve(action): # HITL gate
continue
result = run(action) # act: actually run the tool
state = memory.update(state, action, result) # observe: fold result into state
done = model.is_complete(state)If a prompt was a single model.decide(), an agent puts that inside a while loop and bolts on tools and memory.
The price of autonomy — permissions and verification
This is exactly why OpenClaw was both a sensation and a controversy. Reaching the shell, email, calendar, and messengers requires broad permissions — and those permissions are the risk. A misconfigured or exposed agent leads straight to security and privacy incidents. That's why security researchers flagged OpenClaw's permission model.
The root of the problem is autonomy itself. The moment you hand the loop to the model, it will happily execute the wrong action too. So a production agent needs two things. First, a human-approval gate (HITL) in front of risky actions (payments, deletes, secrets, external publishing). Second, loop caps and verification to stop runaways. The human_approve and is_risky in the code above are exactly those seams. When we operate agents, we require a human to stop in front of financial transactions, irreversible deletes, and secret writes, too.
To sum up
Agents filled the wall the earlier stages couldn't cross (state, tools, verification) with a loop — the model uses tools and iterates by observing results. OpenClaw showed the public the possibility, and at the same time handed over the homework: autonomy needs guardrails.
That homework — running agents safely and at consistent quality — is what calls the next stage. Designing tools, hooks, guardrails, and verification around the model: harness engineering.
Sources: CNBC — the rise and controversy of OpenClaw · OpenClaw (Wikipedia)
More posts
Open Models — Owning the Model Layer Itself
The final stage of the evolution — own the model instead of renting it. Nous Research Hermes (4.3, open weights), the Hermes function-calling standard, and the data flywheel a harness produces to tune a domain model — with code.
Harness Engineering — What Makes the Same Model Behave Differently
Running agents safely and consistently is about the harness around the model — scoped tools, hooks, context layering, verification loops, executable knowledge. The MCP server we built (self-call = SSOT) and hook patterns, in code.
Vibe Coding — Erasing the Friction of Building
Vibe coding, the term Karpathy popularized — describe the intent and the LLM writes the code. What it solved, where it breaks, and how to bolt a verification loop (isolate, run, check) onto it — with code.